EXPERIMENTAL RESULTS
Results across Languages
Violin plots comparing structural metrics of real dependency trees vs. randomly generated baselines with matched crossing counts.
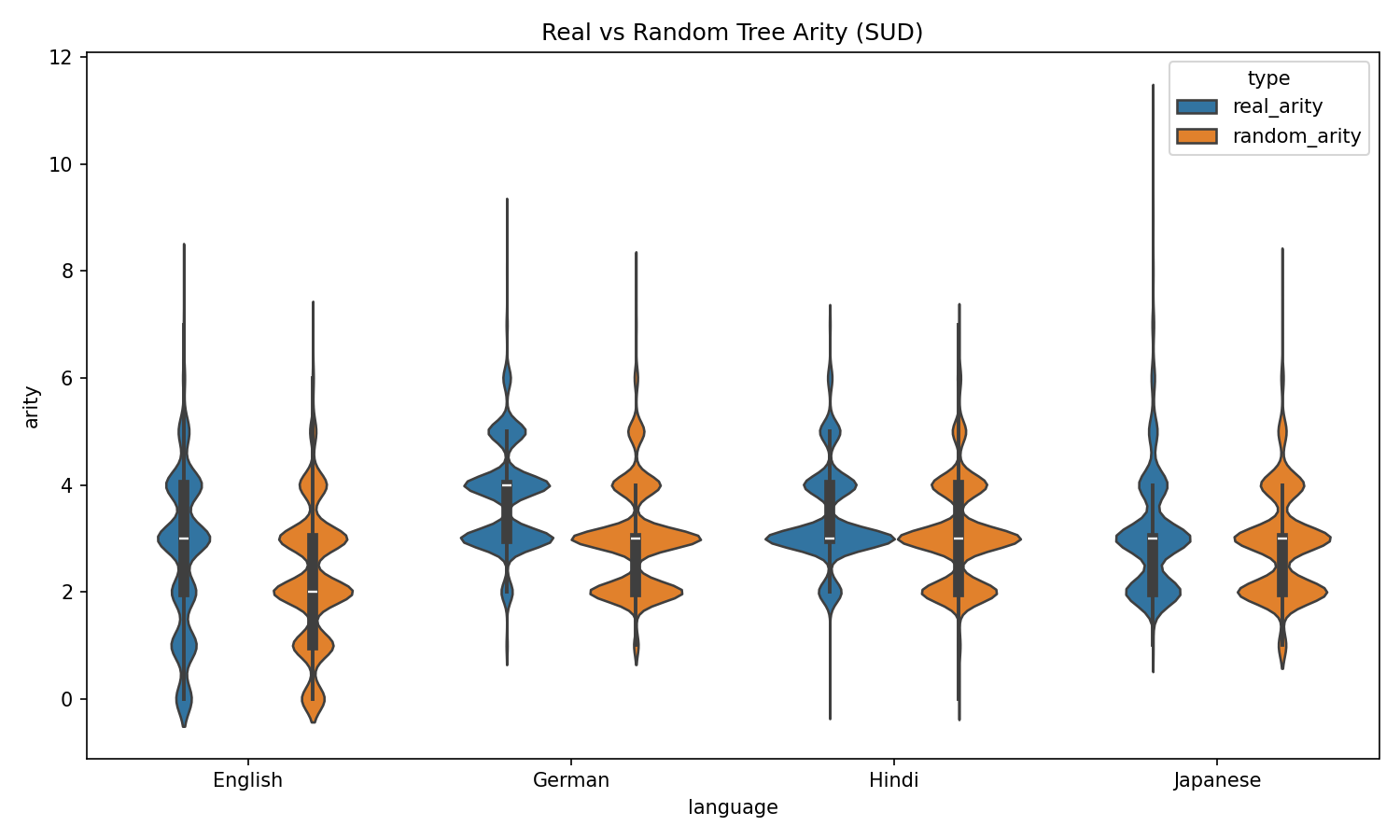
Tree Arity Comparison
Real trees exhibit significantly higher arity (max branching factor) than random baselines across all four languages, suggesting natural languages prefer wider, flatter structures.
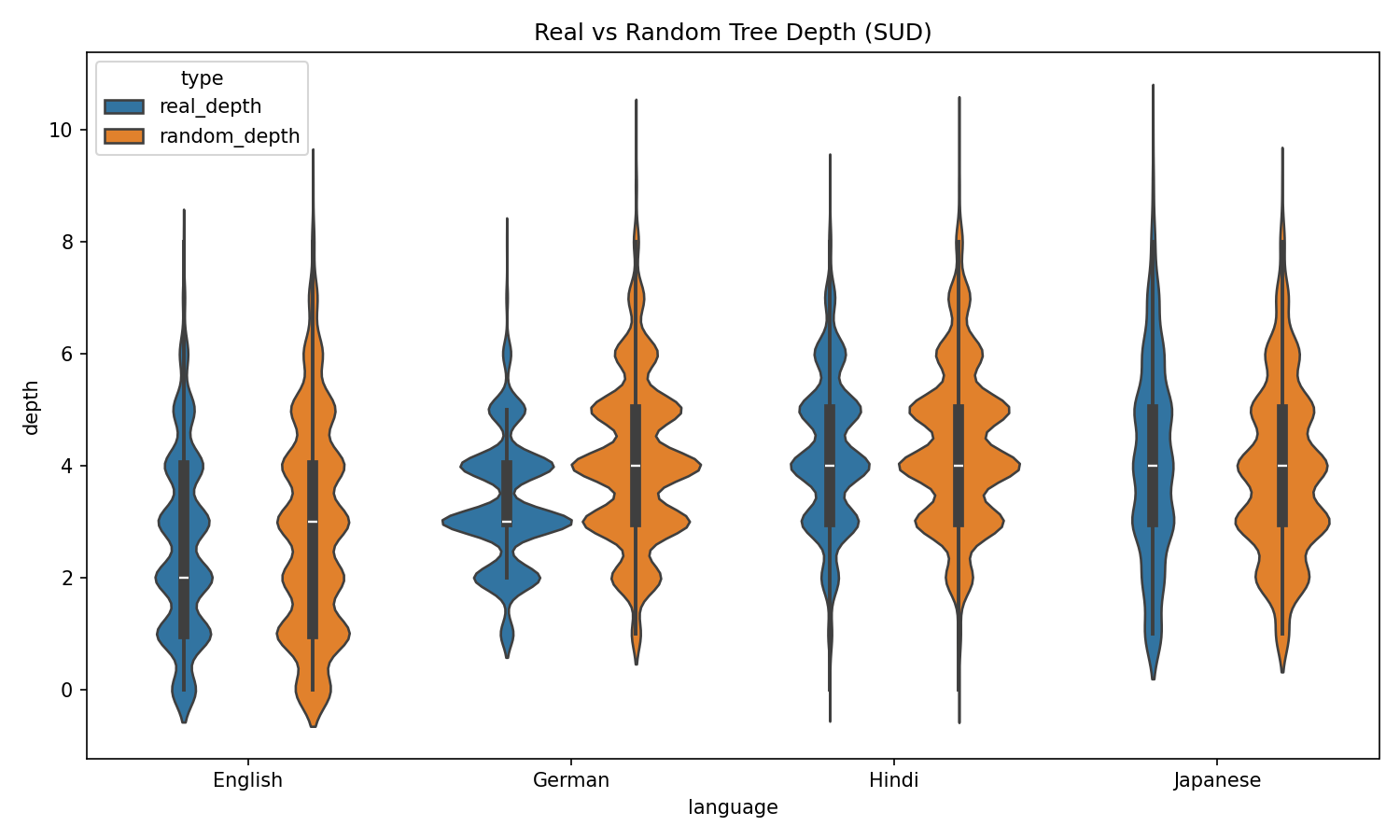
Tree Depth Comparison
Real dependency trees are consistently shallower than random counterparts, indicating that human sentence structures minimize deep nesting — likely for cognitive efficiency.